資料內(nèi)容:
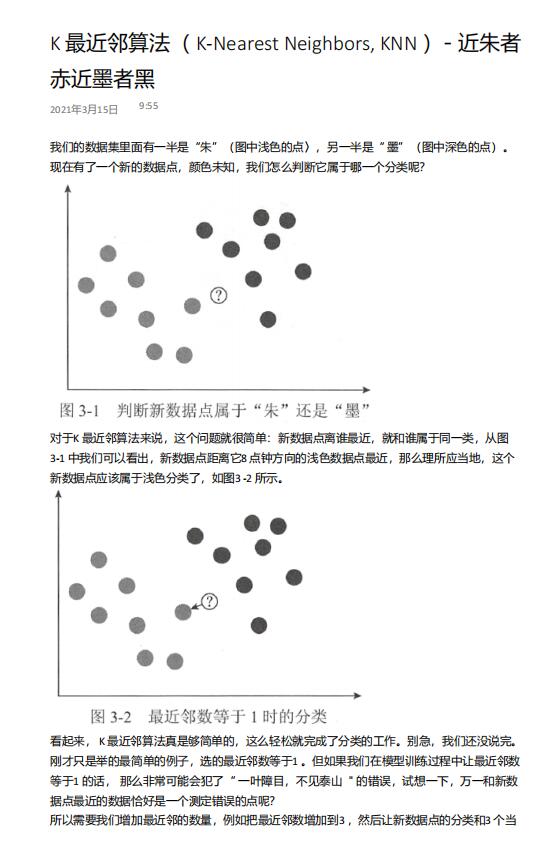
我們的數(shù)據(jù)集里面有一半是“朱”(圖中淺色的點〉,另一半是“ 墨”(圖中深色的點)。
現(xiàn)在有了一個新的數(shù)據(jù)點,顏色未知,我們怎么判斷它屬于哪一個分類呢?
對于K 最近鄰算法來說,這個問題就很簡單:新數(shù)據(jù)點離誰最近,就和誰屬于同一類,從圖
3-1 中我們可以看出,新數(shù)據(jù)點距離它8 點鐘方向的淺色數(shù)據(jù)點最近,那么理所應當?shù)?,這個
新數(shù)據(jù)點應該屬于淺色分類了,如圖3 -2 所示。
看起來, K 最近鄰算法真是夠簡單的,這么輕松就完成了分類的工作。別急,我們還沒說完。
剛才只是舉的最簡單的例子,選的最近鄰數(shù)等于1 。但如果我們在模型訓練過程中讓最近鄰數(shù)
等于1 的話, 那么非??赡軙噶?ldquo; 一葉障目,不見泰山 "的錯誤,試想一下,萬一和新數(shù)
據(jù)點最近的數(shù)據(jù)恰好是一個測定錯誤的點呢?
所以需要我們增加最近鄰的數(shù)量,例如把最近鄰數(shù)增加到3 ,然后讓新數(shù)據(jù)點的分類和3 個當

